/aids/ rentries
/aids/ Settings Repository
Then he went up from there to Bethel; and as he was going up the road, some youths came from the city and mocked him, and said to him, “Go up, you bald head! Go up, you bald head!” So he turned around and looked at them, and pronounced a curse on them in the name of the Lord. And two female bears came out of the woods and mauled forty-two of the youths. Kings 2:23
As a way to keep track of notable generation settings that Anons mention in the general, this rentry exists. Be sure to check back from time to time to see what has changed, as everything here is probably going to be amended in some way often. As a rule, assume that whatever settings aren’t included are left at default. While the settings here have been said to work more often than not, the most important thing to remember before using any of these is that Your Mileage May Vary. The current best strategy for GPT-J-6B models (and I’m willing to bet all subsequent models from here on out) is to adjust these settings on the fly. Treat these presets more as playable cards in your deck. It works against you to believe that any of these are “set and forget”.
Finally, please don’t feel compelled to change what’s working for you because of the wide variety of settings presets here. That’s how you become a rampant Linux distro hopper, and nobody likes a Linux distro hopper. If it isn’t broke, don’t fix it. ***
“I don’t know anything!” [Work in Progress]
The language models we’re using to masturbate are fundamentally trained to predict the probability of the next word of whatever is put into it (referred to as context)
However, the model’s default proclivity towards selecting the most likely token for the most recent token means that the model will eventually end up in a never ending loop. That’s where sampling methods come into play, they try to maximize the coherency of output.
So now, with the help of the following resources, I’m going to try to give a rundown of the options we’re working with.
Randomness
Randomness, better known as Temperature, is a sampling method in itself, and concerns dividing logits by a set temperature value before running each arbitrary real number through a SoftMax function that converts those values into probability percentages, thereby obtaining sampling probabilities.
Lower randomness values increase the confidence the model has in it’s highest probability choices, while temperature values larger than one decrease that confidence in relation to the lower probability choices. In other words, the distribution of percentage values changes depending on your temperature value.
So in practice, increasing temperature makes more out there words appear in outputs, which can lead to more verbose and interesting language but can also result in a ‘semantic drift’ where the AI gets caught up on these unconventional terms and goes off its own merry way, or decides to go an unlikely route in a moment of uncertainty.
Lower temperatures make the model increasingly confident in its top choices, while temperatures greater than 1 decrease confidence. 0 temperature is equivalent to argmax/max likelihood, while infinite temperature corresponds to a uniform sampling.
Anecdotally, increasing temperature has been said to speed up the pace of a story and introduce more imaginative outputs, so in moments of monotony it may be wise to temporarily bump it up to keep things interesting. This is effectively what Randomness will be in your stories, a way to pick up the pace of the story or introduce avant-garde language.
Max and Min Output Length
Honestly, these two are pretty clear cut, and the hard limit NAI has of 60 means that the AI most likely won’t be generating enough tokens to lose sight of what it was trying to continue. Set them to however long you want the AI’s responses to be, and call it a day.
Top-K Sampling
Top-K Sampling was created because as we all know relying only on temperature to smooth things out really doesn’t help as much as it frankly should.
The way this one works is it sorts all potential tokens by probability and starts to remove each token from least likely to most likely, stopping only when it reaches the kth token, kth here representing whatever you set the option to. After it shortens it to said k amount of tokens, the probability is redistributed accordingly. Effectively, Top-k tries to condense the amount of possible tokens to choose from by filtering to remove the really unlikely useless tokens.
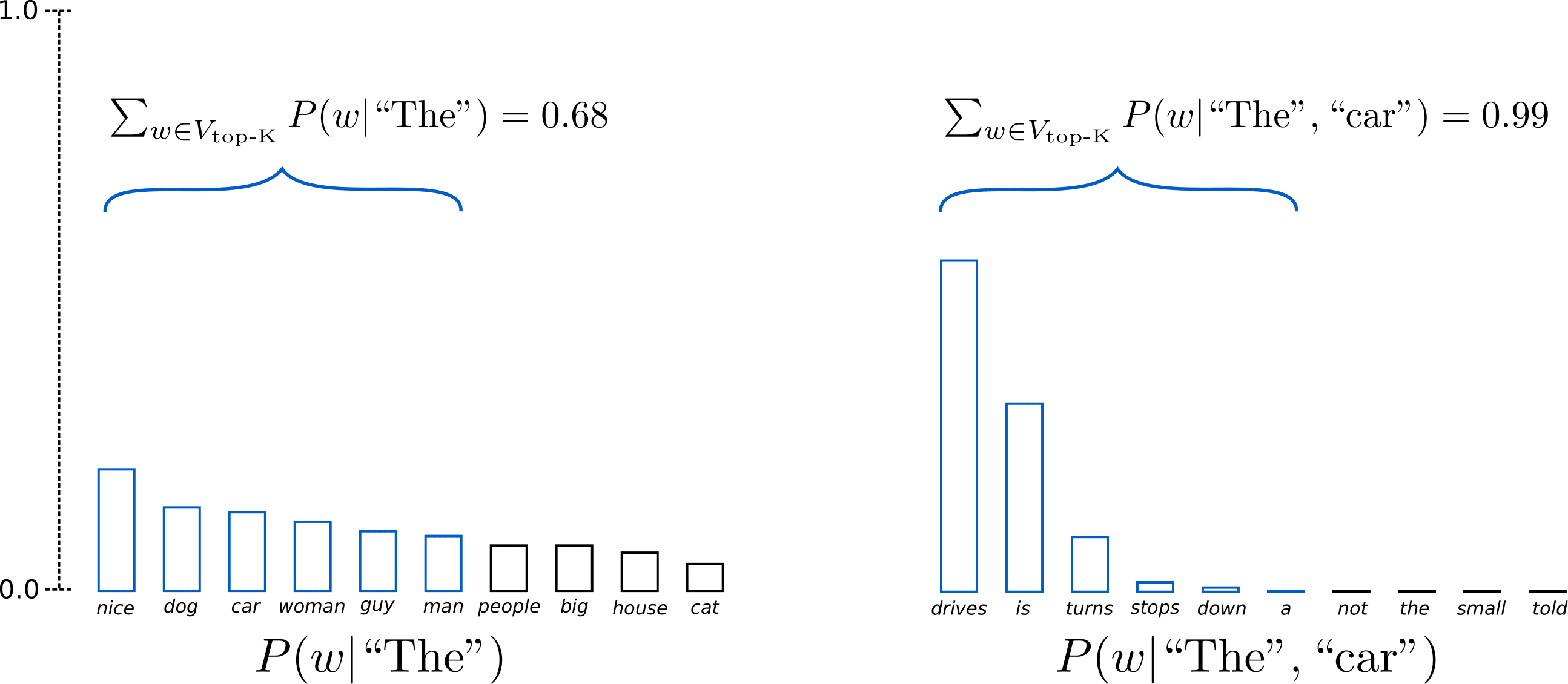
Top-K is okay, but its biggest downside is that it doesn’t change at all for times where there are a range of equally valid choices. Whether your sentence is “I took my dog out for a ____” or “Today, I ate a _____“, Top-K applies the exact same strategy.
Utilize Top-K as an ultimate cut-off point of potential tokens that the model can choose from, it’s not all that good for any other purpose than that. Anything more dynamic is found in Nucleus Sampling.
Nucleus Sampling
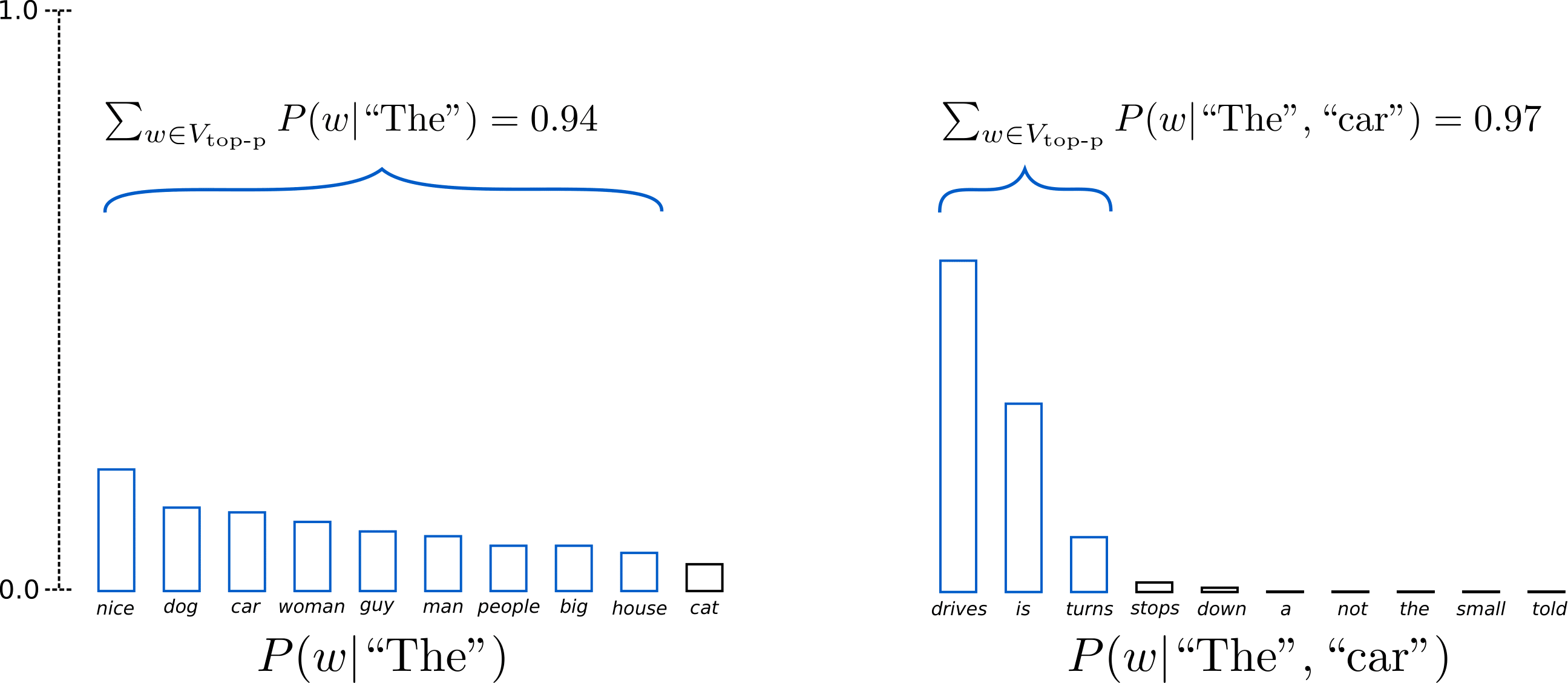
Nucleus Sampling (also known as Top-p Sampling) tackles the issue laid out with Top-k sampling, and it does this by working with a cumulative probability.
Whatever value you set as Nucleus Sampling is the probability percentage target that it wants to reach; it adds the probabilities of tokens and compares the results to find the smallest amount of tokens that exceeds your chosen probability value. That set then becomes the words to choose from.
Having set p=0.92, Top-p sampling picks the minimum number of words to exceed together 92% of the probability mass. In the first example, this included the 9 most likely words, whereas it only has to pick the top 3 words in the second example to exceed 92%.
{kind=link}
This means that Nucleus Sampling accounts for times when the next likely tokens are obvious (the token set may be smaller) and times where there are many equally valid tokens (the token set may be larger)
Even better, this method is often used in tandem with Top-K with Top-K acting as the ultimate cut-off and Nucleus the surgically precise probability calculator to produce a set of very likely next tokens. This is why NovelAI uses both—because it really is best to use them together. You don’t have to, but you probably should.
The Presets
Nucleus Sampling / Top-k Sampling
The Best Guess Settings
Randomness: Adjust as needed between 0.55 and 1
Max Output Length: 60
Min Output Length: 40
Top-K Sampling: 110
Nucleus Sampling: 0.9
Repetition Penalty: 3.1
Repetition Penalty Range: 512
Repetition Penalty Slope: 3.33

The Old Familiar
Randomness: 0.8
Max Output Length: 60
Min Output Length: 20
Top-K Sampling: 50
Nucleus Sampling: 0.9
Repetition Penalty: 2
Repetition Penalty Range: 512
Repetition Penalty Slope: Disabled
Jeral
Finally had a chance to play around with v3, and it needed a different everything to work well. It works so amazingly well with context that I had to move memory, a/n, and lorebook to the top because they were interfering more than helping. Rep pen slope makes outputs a dice roll, either really really good or it will hyperfocus on something you’ve said near the early part of your range, so I disabled it. Story settings are default: trim from top, so are all the other things not visible. Ban tokens if v3 starts doing weird stuff like ellipses after quotes or asterisk overusage. for people on 1024 context plans, if your memory and a/n leak surround them with brackets, but for anything above -20 depth remove them.
Jarel HydroStorm
Randomness: 0.6
Max Output Length: 60
Min Output Length: 20
Top-K Sampling: 80
Nucleus Sampling: 0.65
Repetition Penalty: 3
Repetition Penalty Range: 1472
Repetition Penalty Slope: Disabled

The /aids/ Variant
For now, Context Settings and Lorebook Settings remain the same as Jeral
I’m not an expert by any means and I don’t have any default sliders because I’m constantly fiddling with them. But as a base I’m using Jarel’s V3. Crank randomness up (Between 1 to 2) and Top-K/Nucleus down. 40-50ish and 0.5ish respectively. Top-K/Nucleus set lower seems to prevent word salad that high randomness typically shits out on its own. Still testing but I’m liking what I’m seeing. The defaults for ModifiedJeralV3 are intended to serve as a baseline. As you crank randomness up, fiddle with turning Top-K and Nucleus sampling down. General conclusion: Higher randomness benefits from lower Top-K and Nucleus Sampling.
Randomness: 1.5
Max Output Length: 60
Min Output Length: 20
Top-K Sampling: 40
Nucleus Sampling: 0.5
Repetition Penalty: 3
Repetition Penalty Range: 1472
Repetition Penalty Slope: Disabled

If it’s not really conveyed in the image I want to be clear that the slider settings for Randomness, Top-K, and Nucleus sampling are very much not “de facto”. Play around with them. I’m still experimenting myself.
Optimal Moth
Since I wasn’t satisfied enough with my previous settings, and after trying some of Jarel’s new ones above, I’ve got this updated set of settings partially based on Jarel’s that should work fine with his context settings too, probably. It will depend on context and other settings, but for me with only two lorebook entries, memory and some story context, the generated writing was pretty interesting to read, randomness can be played around with some more though, my goal behind these settings was to get good, coherent writing at high randomness! Edit: After some testing with a fresh prompt, can confirm that the writing is mediocre until there’s enough context built up for the AI to go off of, so either make sure you have enough context, or apply the set after you generate some story!
Nyks
Randomness: 1.07
Max Output Length: 60
Min Output Length: 40
Top-K Sampling: 75
Nucleus Sampling: 0.475
Repetition Penalty: 5.225
Repetition Penalty Range: 1264
Repetition Penalty Slope: Disabled
Sensible Moth
One more set of settings for now. Took it up as a challenge to make 2.5 randomness output writing that made sense. Nucleus is what keeps the randomness tame, so adjust at your own discretion, also avoid using Tail-Free Sampling with it, it does not play well with high randomness no matter how you adjust it. May require more direction and occasional correction to keep on track, but writing style is interesting. Usually needs good context as a primer.
Nyks
Randomness: 2.5
Max Output Length: 60
Min Output Length: 40
Top-K Sampling: 58
Nucleus Sampling: 0.35
Repetition Penalty: 2.45
Repetition Penalty Range: 1280
Repetition Penalty Slope: Disabled
I’m getting surprisingly coherent responses from these settings. I’m using Best Guess setting for Advanced Context, though, as those weren’t provided.
Experimental Moth
This is based on my last ‘Sensible Moth’ preset, but to fully utilize this one, you should use the notes format people over at #community-research found in Author’s Note. It goes as [ Author: George R.R. Martin ; Tags: second person, adventure ; Genre: Fantasy ; ]. If you don’t have anything to put into any of these, instead of leaving them out, leave them blank like so [ Author: ; Tags: adventure ; Genre: Fantasy ; ]. The spaces are important, and capitalization matters! Still needs to build up some context before the generation gets good.
Nyks
When it understands, it’s stronger than Sensible Moth. You have to be especially careful on word choice, but can produce some really good results once you’ve got it under control. The outputs are ‘sensible’ but often become ‘sensibly incorrect’ quickly.
Randomness: 2.5
Max Output Length: 60
Min Output Length: 40
Top-K Sampling: 25
Nucleus Sampling: 0.425
Repetition Penalty: 2.45
Repetition Penalty Range: 528
Repetition Penalty Slope: Disabled
As is typical of a high randomness setting it’s not exactly suited for standard plot progression and can require a few rerolls, but if you like to be surprised it’s pretty fun to use during wild sex scenes. It also seems more willing to describe and bring up the defining physical features of characters, as well as incorporate them into the sex scenes quite often. I’m guessing this is due to the lower Repetition Penalty settings giving the AI more leeway about how it describes things. Whatever the case. Thumbs up from me.
Whitepaper
These are dead simple classic style generation settings slightly improved based on my knowledge and the fine level of control NAI gives us. These settings should give you the highest averaged score of 4 human ratings: Interest, coherency, fluency and relevancy. Default rep penalty hasn’t been touched. High penalty may not be necessary with high randomness, yet coherent nucleus settings like this. If you’re having problems with AI displaying your lorebook colors wrong, Capitalizing the Color inside your lore may help. These settings should be model agnostic.
Randomness: 0.72
Max Output Length: 44
Min Output Length: 6
Top-K Sampling: Disabled
Nucleus Sampling: 0.725
Repetition Penalty: 3.0
Repetition Penalty Range: 1024
Repetition Penalty Slope: 6.57
Fated Outcome
This Preset will always return the same output until something is changed in the Context, allowing a sense of permanence and fate within the world of your narrative.
Fun cases with this Preset include “time warping” to see how a character would have reacted if you said or did something different, and testing the effects of different token associations on the flow of a Story. Additionally, lore details and names should have a significantly higher chance of being correct.
NOTE: This Preset makes the Retry button useless while active, as the same output will always be returned until something changes.
Randomness: 0.1
Max Output Length: 400
Repetition Penalty: 2.4
Top-K Sampling: 1
Nucleus Sampling: 0.1
Tail-Free Sampling: off
Repetition Penalty Range: off
Repetition Penalty Slope: off
Min Output Length: 1 tokens
Tail-Free Sampling
Coherent Creativity
This has been extensively tested, and is adjusted as needed for different scenarios. It has shown itself to be a good balance between coherence, creativity, and quality of prose in my scenarios.
Using TFS and a higher than default randomness to have some creativity and variability. An even amount of repetition penalty is applied across the entire context of 2048 tokens. This is because the way repetition penalty slope works and is used, it makes no sense – a lot of lorebook context is loaded at the top of the context, where repetition penalty is not applied in most settings.
Without even repetition penalty across the entire context, you end up with a lot of exposition word for word from lorebook entries. You might introduce a middling repetition penalty slope if you run into difficulty.
Randomness: 0.52
Repetition Penalty: 3.875
Top-K Sampling: off
Nucleus Sampling: off
Tail-Free Sampling: 0.992
Repetition Penalty Range: 2048
Repetition Penalty Slope: off
Damn Decent
Randomness: 0.56
Max Output Length: 60
Min Output Length: 20
Tail-Free Sampling: 0.694
Repetition Penalty: 3.15
Repetition Penalty Range: 1168
Repetition Penalty Slope: 1.89
Complex
Been getting really good results with these settings, based off of the “Complex Readability Grade” posted in Basileus’ findings in #novelai-research. With good usage of Tone, Word Choice and maybe Author in the Author’s Notes, as well as a decent amount of context for the AI to consider after starting a story, you can get some stunningly evocative prose while the story’s progression remains pretty consistent. Of course, it will still need guidance from time to time, and it might require some slight adjustments to Randomness and TFS occasionally based on your preferences, but I think this is going to be my go-to for serious stories until somebody finds a setting preset that’s even better than this.
Orion
Randomness: 0.83
Max Output Length: 60
Min Output Length: 40
Tail-Free Sampling: 0.674
Repetition Penalty: 3.5
Repetition Penalty Range: 1024
Repetition Penalty Slope: 5.13
Pleasing Results
Randomness: 0.45
Max Output Length: 60
Min Output Length: 40
Tail-Free Sampling: 0.9
Repetition Penalty: 3.35
Repetition Penalty Range: 1024
Repetition Penalty Slope: 6.75

The Scaffold
Yes, another thing yanked from the community research discord.
Remember Notes++? Remember how effective it was to be able to stagger information through context? Fortunately, NAI provides enough options for users to recreate such a feature, and as a result, a few mongaloids discord users have developed a general rule of thumb for proper Lorebook placement. It’s best to view this as inspiration rather than gospel, and it was first conjured during Sigurd V2’s reign of terror, but it’s worth a look.
The scaffold was designed by OPVAM’s and is meant to be a guideline on what advanced settings you should set for each lore entry (and advanced context settings). What the scaffold is trying to achieve is to insert the lore as close to the front/bottom of context as possible, but still allow the story some “breathing room” in between the lore. TravellingRobot
| Position | Insertion Order | Reserve Tokens | Type |
|---|---|---|---|
| -12 | -100 | 200 | Memory |
| -10 | -200 | 100 | Lore: Concepts |
| -10 | -300 | 100 | Lore: Places |
| -10 | -400 | 100 | Lore: Races |
| -10 | -500 | 100 | Lore: Factions |
| -8 | -600 | 200 | Lore: Author’s Note (Impromptu Lorebook Entry) |
| -6 | -700 | 100 | Lore: Characters |
| -4 | -1000 | - | Lore: *** (Forced Activation) |
| -4 | -800 | 200 | Author’s Note - The ‘Real’ One |
| 0 | 0 | 512 | Story |
Note on token limit (ght901)
Just as a note for people using these settings. If you don’t keep the tokens used by that Lorebook entry under the number of reserved tokens it will be almost guaranteed (there’s a small chance the first might not) to be trimmed.
This rentry is designed and updated with Sigurd in mind.